How NOT to Build a Data Science Project
 The Absolute No-No’s of a Data Science project (Photo by Dimitri Houtteman on Unsplash)
The Absolute No-No’s of a Data Science project (Photo by Dimitri Houtteman on Unsplash)
(Originally published on Towards Data Science)
I knew I was doing something wrong.
I had built up a repertoire of interesting, practical projects. I had a couple of online courses to showcase what I had learnt. I even built a portfolio website to showcase all my projects and articles (which you can access here).
But, I still felt a gaping hole in the knowledge I had. A huge, gaping, chasm-sized hole. I felt like something major was missing from the equation.
That’s when I came across some absolutely amazing playlists on YouTube on building an End-to-End Data Science project from scratch. Some great examples are this one by Ken Jee, this one by Daniel Bourke and this one by Data Professor. (Shout out to all of them for some absolutely brilliant content!)
I realized I needed to get started on an End-to-End Data Science project, stat (pun very much intended). Getting hands-on and diving right in, though uncomfortable at first, is the best way to learn something new.
And so I dove straight in.
Until I got stuck. Again.
And again.
And again.
But finally, after hours of toiling, a couple dozen Stack Overflow searches (thank the heavens for Stack Overflow) and a lot of banging my head against the wall out of frustration after running into a wall of errors (this didn’t help as much), I was done.
You can check out my final project here. It’s a Data Science Salary Predictor (inspired and guided by Ken Jee’s playlist). I’m also working on a couple more of my own, this time with no reference or guidance, to really push myself beyond the perceived limits of my understanding.
During the process of building these projects, I learnt a whole lot, not only from a Data Science point of view, but also about how to tackle the problem of structuring such a project in the first place; by making a lot of mistakes and learning from them, again and again.
Here are some of the mistakes I had made before, and what you can do to avoid these mistakes in your next project:
Mistake #1: Not making my projects End-to-End.
Typically, most of the time spent on real-life applications of Data Science is on Data Cleaning and Preparation. In fact, it’s widely been acknowledged that about 80% of the time spent is on cleaning the data and transforming into a form suitable for further analysis.
As annoying as it may be, Data Cleaning is an essential step in the Data Science life cycle. Not all the datasets you might work with in a real job or internship will be as cleaned and ready to use as a Kaggle dataset.
It might be very messy, and it might possibly be your job to clean it up and make it ready-to-use.
And an equally important part of the project is productionizing and deploying projects. There’s a quote I’m seeing more and more of these days:
Your project shouldn’t end its life in a Jupyter Notebook.
Building projects and products that can be accessed by other people is one of the main uses of Data Science.
A bunch of code in a Jupyter Notebook is typically of no practical use, but building a simple Web Application using a powerful and easy-to-use tool like Streamlit or a slightly more complex tool like Flask, to showcase what you built, just that little bit of extra effort, makes it a lot easier for people to see what you’ve built.
It’s very important to start with strong foundations and end with a tangible, practical product.
Pro Tip: Get your own data (web scrape if you have to). Clean it, preprocess it, do some feature engineering. And don’t forget to productionize your project with Streamlit or Flask.
Mistake #2: Not spending time on the things that matter most.
Pareto’s principle (also known as the 80–20 rule) states that, for many events, around 80% of the effects come from 20% of the causes. Similarly, in a project, around 80% of the value comes from just 20% of the things you do. Equivalently, what this also means is that around 80% of the things you might do don’t really add a whole lot of value (around 20% only).
I used to spend a lot of my time thinking and analyzing about the different options or different paths I could take with my project.
I shouldn’t have.
I should have just gotten started with something. I could have dealt with the after-effect of having chosen the wrong option, later.
A simple example of where I’ve wasted a lot of time: Cloud providers.
If you’re with me so far, productionizing a project using Streamlit or Flask is very important. But also, deploying that project so that it can be accessed by everyone is also equally important.
And there are a lot of options out there to do this.
I started obsessively analyzing and researching all the different options to help deploy my project. Looking up all the differences between AWS and GCP, the pros and cons for each, what instances they provide, what costs I might have to incur, and so on.
Until I realized the mistake I was making. I just had to deploy it, period. It didn’t matter where.
So, I deployed it on Heroku for free. (They allow one free deployment, which I graciously used).
Next time, I’ll deploy it on whatever I find to be the easiest. No second thoughts.
Pro Tip: Stop thinking, start doing. Use the 80–20 rule to your advantage.
Mistake #3: Not planning what the end result will look like.
If I’ve managed to convince you by now that productionization and deployment are invaluable steps in your project life cycle and about the power of the 80–20 rule, then another equally important and frequently overlooked step is planning what the final result is going to look like.
Okay, let’s assume you’ve agreed with my logic so far and you’ve decided you want to build a web application showcasing your project.
But what is that application going to do?
Ask yourself questions about the UI, such as:
- What are the inputs it takes from the user?
- In what form are you going to take in the inputs?
- What’s the end result your model is gonna spew out?
- What form is the output going to be in?
- Are there any additional features that I could add that will make the user experience better?
- Are there some things I should avoid at all costs?
During my Data Science Salary Predictor project, I made the grave mistake of not thinking about the final interface and its layout. When I finally got to that stage, I saw that the user’s categorical inputs would make no sense to my model, so I had to go back and change certain categorical variables into ordinal variables, wasting some valuable time in the process.
Answering these questions at the beginning will save a whole lot of time later on, and it will avoid you having to go back and forth between the different steps unnecessarily. I use the word ‘unnecessarily’ here for a reason, which brings me to Mistake #4.
Pro Tip: Have a rough idea of the end-result when you start, in whatever form it may be. Sketch it out somewhere if you have to.
Mistake #4: Not circling back to previous stages.
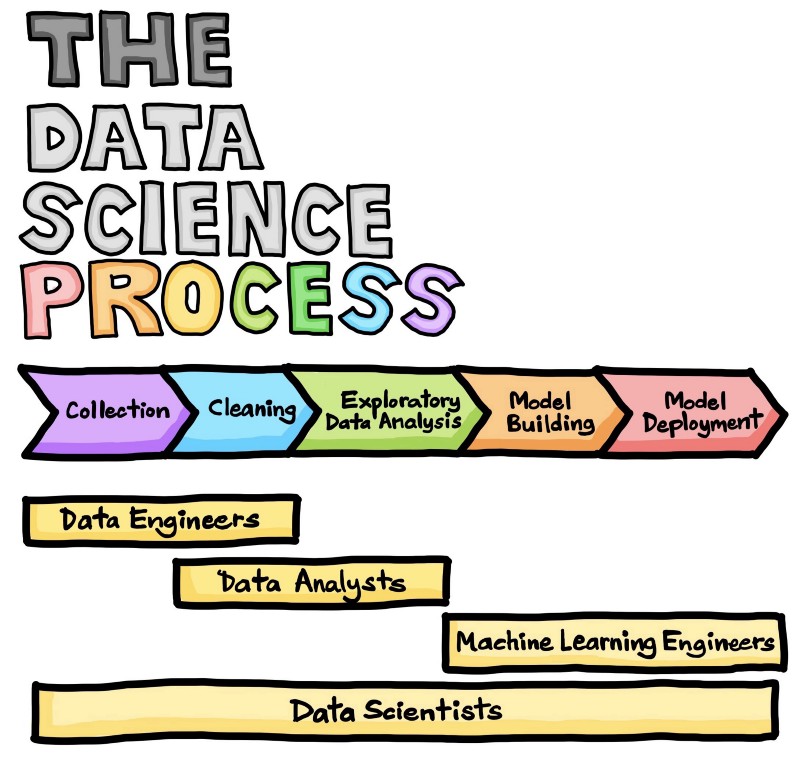
Typically, any project can be categorized into these 5 major stages: Data Collection, Data Cleaning, Exploratory Data Analysis, Model Building and Model Deployment.
But a major mistake I made was thinking that the process was a linear series of steps, when in fact, it’s an iterative and often, cyclical process.
As an example, during my Data Science Salary Predictor project, when I was at the Model Building stage, I thought of a couple more interesting features that I could have added, to give as inputs to my model.
So what did I do?
I went all the way back to the Data Cleaning and Preprocessing step, had to do some additional feature engineering, and had to perform some Exploratory Data Analysis on the new data, and build another model with the additional features.
Sometimes, these circling backs might be completely unnecessary, such as in Mistake #3.
But sometimes, you might have a new insight after having worked with the data for a while and in that case, circling back is the right thing to do.
Pro Tip: Plan as much as necessary before hand, but circle back if needed. That little effort might make your project a lot better, for all you know.
Mistake #5: Not introspecting and evaluating after the project is deployed
A step I neglected completely, and what might actually be the most important step of them all, is evaluating your project after you’re done.
Seeing what went right, what went wrong, and how to improve next time.
I learnt this about this very important step from Daniel Bourke’s video after the Airbnb project he had embarked upon.
Take some time, analyze all the steps of your project, introspect, learn from them and move on.
This article wouldn’t exist without this step. The mistakes listed here are those that I learnt from my projects, and I’m almost sure that anyone embarking on a project of their own will commit certain mistakes along the way. Learn from them, make sure you don’t repeat them next time, move on.
Pro Tip: Go back and see what went right and wrong, and learn from them.
“It is okay to mistakes, as long as you learn from them.” — Anonymous
And most importantly: don’t forget to have fun along the way.
Feel free to reach out to me on LinkedIn, check out my GitHub for the projects I’ve done, or my personal website for all my work.